Extractive Summarization Using Supervised and Semi-supervised Learning
published in 2008 Coling
这篇文章提出一种学习方法,并把五种特征进行组合进行验证。虽然实验结果还不错,但是由于需要大量的训练数据,于是还提出了一种cotraining的方法,该方法利用标注数据和非标注数据进行组合,节省了标注。
###Introduction
####脉络
先介绍自动文摘的概念,然后介绍两类文摘的方法。其中抽象型文摘由于需要对文章的深度理解,但是自然语言处理技术并不够先进,所以只在个别领域比较好。于是抽取型的摘要就是研究的主流。
由于各种特征被陆续的提出,而句子的特征不可能是独立起作用的,于是本文将组合各种特征进行验证。
由于有监督的训练是需要大量的标注工作的,于是本文提出了co-training的方法进行辅助训练,降低对标注数据的要求。两个分类器迭代训练,降低标注时间。
1997年,文档结构特征。
2000年,signature terms被提出。
2004年,位置特征、长度特征被提出并证实有用。
2004年,内容特征(centroid)。
2006年,高频词特征。
2004年,句子相似度、PageRank被考虑。
关于co-training
1998年,提出co-training思想
2001年、2003年、2004年很多应用在用co-training思想
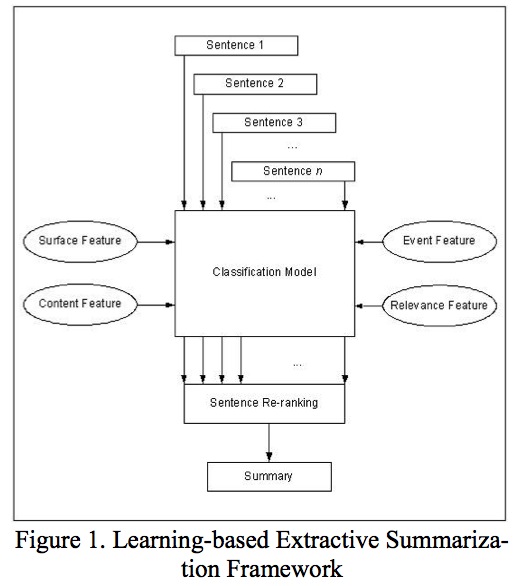
文档抽取框架
###特征
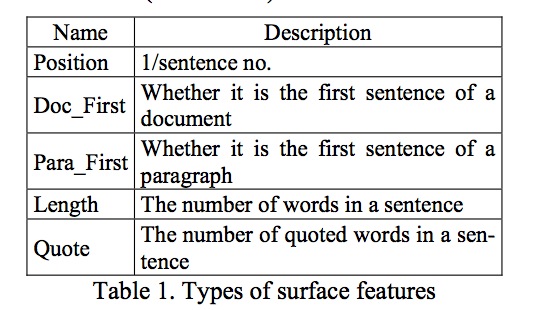
####Surface Features
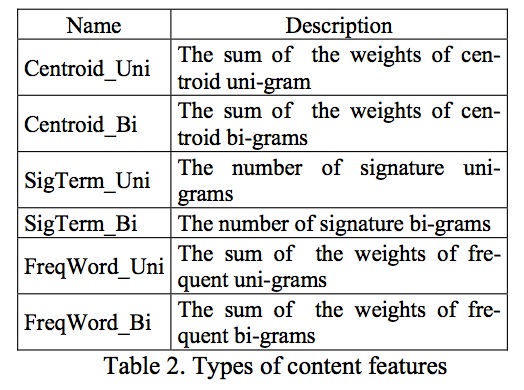
####Content Features
####Event Features
一个事件由事件词和相关的元素组成,动词和action词作为事件词特征。
给定一个数据集,找出其中的事件词和事件元素词。针对每个事件利用PageRank来计算各个节点的权重,然后一个句子的权重就是其中包含词的累计。
####Relevance Features

###试验方法
采用PSVM来做训练器,co-training的部分则是PSVM+NBC进行组合。

其实就是在标注数据上训练两个分类器 PSVM和NBC,然后各自来对未标注数据进行预测,将可信度最高的那些数据放入已标注数据集,然后重复训练,直到未标注数据集都干净了为止。
###实验
在DUC2001上实验
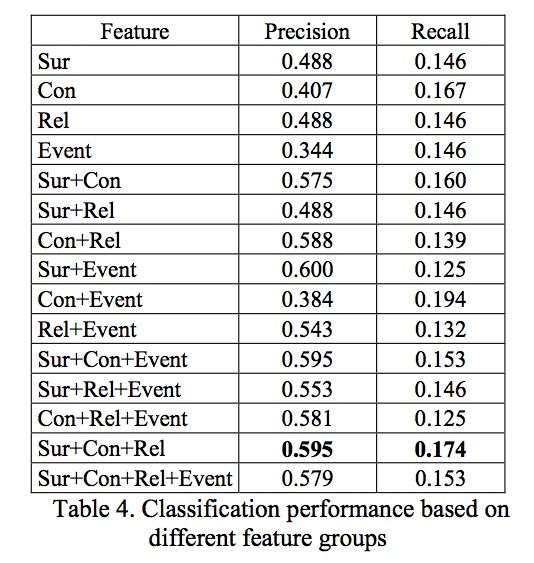
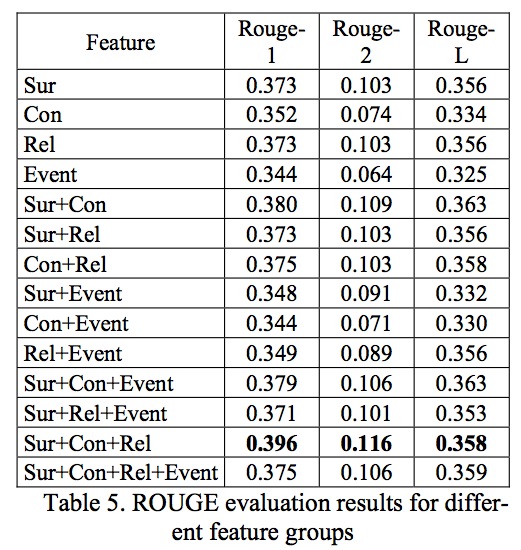
说明不管怎么看都是Sur+Con+Rel的效果是最好的,而且R-1差不多是R-2的3倍。
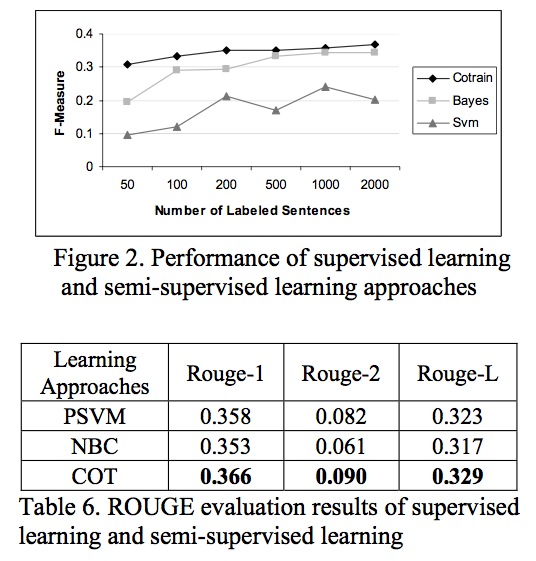
对于Co-training来说,由于不断的增加训练样本,效果也是不错的。